


Il machine learning è una tecnica di analisi di dati che insegna ai computer a svolgere un’attività naturale per l’uomo e gli animali: imparare dall’esperienza.
Gli algoritmi di machine learning usano metodi computazionali per “apprendere” le informazioni direttamente dai dati senza basarsi su un’equazione predeterminata come modello. Essi possono migliorare in modo adattivo le loro prestazioni man mano che aumenta il numero di campioni disponibili per l’apprendimento.
Perché il machine learning è importante
Con l’aumento dei Big Data, l'apprendimento automatico è diventato una tecnica fondamentale per la risoluzione di problemi in diversi settori, tra cui:
- elaborazione di immagini e visione artificiale: per il riconoscimento facciale, la rilevazione del movimento e l’identificazione di oggetti;
- biologia computazionale: per la diagnosi di tumori, la ricerca farmaceutica e il sequenziamento del DNA;
- produzione di energia: per le previsioni di prezzo e carico;
- settore automobilistico, aerospaziale e manifatturiero: per la manutenzione predittiva;
- elaborazione del linguaggio naturale: per le applicazioni di riconoscimento vocale.
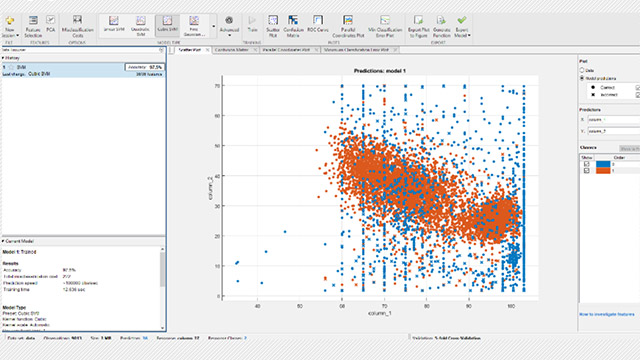
Come funziona il machine learning
Vengono utilizzati due tipi di tecniche: l’apprendimento con supervisione, che addestra un modello in base a dati di input e output noti per consentirgli di prevedere output futuri, e l’apprendimento senza supervisione, che individua pattern nascosti o strutture intrinseche nei dati di input.
Apprendimento con supervisione
Il machine learning con supervisione costruisce un modello in grado di effettuare previsioni sulla base di prove attendibili in caso di incertezza. Un algoritmo di apprendimento con supervisione utilizza un set conosciuto di dati di input e risposte note ai dati (output) e addestra un modello per generare previsioni accettabili in risposta ai nuovi dati.
L’utilizzo dell’apprendimento con supervisione è consigliato se si dispone di dati noti per l’output che si desidera prevedere. L’apprendimento con supervisione utilizza le tecniche di classificazione e regressione per sviluppare modelli predittivi.
Le tecniche di classificazione prevedono risposte discrete: ad esempio, se un’e-mail è autentica o spam, oppure se un tumore è maligno o benigno. I modelli di classificazione raggruppano i dati di input in categorie. Tra le applicazioni più comuni figurano l’imaging medicale, il riconoscimento vocale e la valutazione del rischio di credito.
Usa la classificazione se i tuoi dati possono essere etichettati, categorizzati o suddivisi in classi o categorie specifiche. Ad esempio, le applicazioni per il riconoscimento della scrittura a mano utilizzano la classificazione per riconoscere lettere e numeri. Nell’elaborazione di immagini e nella visione artificiale, le tecniche di Pattern Recognition senza supervisione vengono utilizzate per la rilevazione di oggetti e la segmentazione di immagini.
Tra gli algoritmi di classificazione più comuni figurano support vector machine (SVM), k-nearest neighbor, Naïve Bayes, analisi discriminante, regressione logistica e reti neurali.
Le tecniche di regressione prevedono risposte continue: per esempio, variazioni della temperatura o fluttuazioni della domanda di energia. Le applicazioni tipiche includono la previsione del carico elettrico e il trading algoritmico.
Utilizza le tecniche di regressione se lavori con un intervallo di dati o se la natura della tua risposta è un numero reale, per esempio la temperatura o il tempo rimanente al verificarsi di un guasto di un’attrezzatura.
Tra gli algoritmi di regressione più comuni figurano il modello lineare, il modello non lineare, la regolarizzazione, la regressione stepwise, le reti neurali e l’adaptive neuro-fuzzy learning.
Apprendimento senza supervisione
L’apprendimento senza supervisione individua pattern nascosti o strutture intrinseche nei dati. Viene utilizzato per fare deduzioni da set di dati che includono dati di input senza risposte etichettate.
Il clustering è la tecnica di apprendimento senza supervisione più comune. Viene utilizzata nell’analisi esplorativa di dati per individuare pattern nascosti o raggruppamenti nei dati. Tra le applicazioni dell’analisi cluster figurano l’analisi della sequenza genetica, le ricerche di mercato e il riconoscimento di oggetti.
Ad esempio, se una società di telefonia cellulare desidera ottimizzare le posizioni di installazione delle sue antenne, può utilizzare il machine learning per stimare il numero di cluster di persone che si collegano alle sue antenne. Un telefono può collegarsi con una sola antenna alla volta, per cui il team utilizza gli algoritmi di clustering per progettare la migliore posizione delle antenne per cellulari in modo da ottimizzare la ricezione del segnale per gruppi, o cluster, di clienti.
Tra gli algoritmi di clustering più comuni figurano k-means e k-medoids, clustering gerarchico, modelli di mistura gaussiana, modelli di tipo hidden Markov, self-organizing maps, clustering fuzzy c-means e clustering sottrattivo.
Come decidere quale algoritmo utilizzare?
La scelta dell’algoritmo giusto può sembrare un arduo compito, dal momento che esistono decine di algoritmi di machine learning con e senza supervisione e ognuno di essi utilizza un diverso approccio di apprendimento.
Non esiste un metodo migliore, né un metodo che valga per tutti. In parte, la ricerca del giusto algoritmo viene fatta per tentativi ed errori; neppure i data scientist più esperti sono in grado di dire se un algoritmo possa funzionare o meno senza averlo testato. Ma la scelta dell’algoritmo dipende anche dal formato e dal tipo di dati utilizzati, dalle informazioni che si desidera ottenere dai dati e da come queste informazioni verranno utilizzate.
Ecco alcune linee guida per la scelta tra l'approccio con supervisione e senza supervisione:
- scegli l’apprendimento con supervisione se desideri addestrare un modello per fare una previsione (per esempio, il valore futuro di una variabile continua, come la temperatura o il prezzo di un’azione) o una classificazione (ad esempio, identificare la marca di un’automobile dal filmato di una webcam);
- Scegli l’apprendimento senza supervisione se desideri analizzare i tuoi dati e addestrare un modello per trovare una buona rappresentazione interna, per esempio suddividendo i dati in cluster.
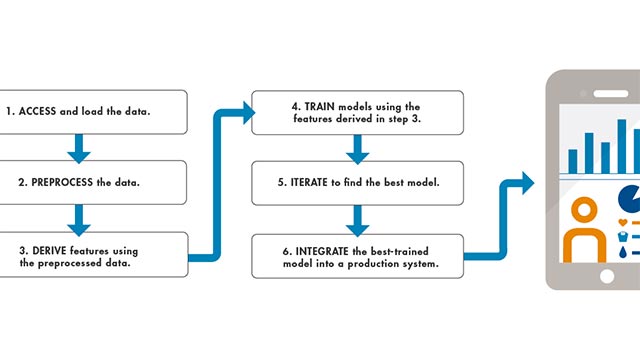 Machine Learning con MATLAB
Machine Learning con MATLAB
Come si può sfruttare l’efficienza del machine learning per utilizzare i dati e prendere decisioni migliori? Grazie agli strumenti e alle funzioni per la gestione dei Big Data, MATLAB è un ambiente ideale per l’applicazione del machine learning all’analisi dei dati.
MATLAB garantisce a progettisti e data scientist l’accesso immediato a funzioni predefinite, a un’ampia scelta di toolbox e app specializzate per la classificazione, la regressione e il clustering.
MATLAB consente di:
- confrontare approcci quali la regressione logistica, gli alberi di classificazione, le support vector machine, i metodi di ensemble e il deep learning.;
- utilizzare le tecniche di affinamento e riduzione dei modelli per creare un modello preciso in grado di sfruttare al meglio il potere predittivo dei tuoi dati.;
- integrare i modelli di machine learning nei sistemi enterprise, nei cluster e nei Cloud, e utilizzare i modelli per hardware embedded in real time;
- eseguire la generazione di codice automatica per l’analisi di sensori embedded;
- supportare i flussi di lavoro integrati, dall’analisi dei dati alla distribuzione.


{kind=link}