


Il reinforcement learning è una branca del machine learning in grado di risolvere problemi decisionali complessi. Per capire il potenziale ruolo che questa tecnologia può assumere in un progetto, dobbiamo prima di tutto rispondere a tre domande fondamentali:
- Che cos’è il reinforcement learning?
- Quando si usa il reinforcement learning?
- Qual è il flusso di lavoro da seguire per risolvere un problema di reinforcement learning?
Che cos’è il reinforcement learning?
Il reinforcement learning aiuta un computer (agente) ad apprendere un comportamento tramite ripetute interazioni di tipo “trial-and-error” (eseguite per tentativi ed errori) con un ambiente dinamico. Questo approccio consente all’agente di attuare una serie di decisioni in grado di massimizzare una metrica di ricompensa per l’attività, senza essere esplicitamente programmato per tale operazione e senza l’intervento dell’uomo.
Pensiamo di voler posteggiare l’auto con un sistema di parcheggio automatizzato. L’obiettivo di questa attività è che il computer del veicolo (l’agente) posteggi l’auto nell’apposito spazio. La Figura 1 mostra una panoramica generale di un sistema di reinforcement learning.
In questo scenario, tutto ciò che è al di fuori dell’agente, compresa la dinamica del veicolo, i veicoli circostanti, le condizioni atmosferiche, ecc. fa parte dell’ambiente. Durante l’addestramento, l’agente si serve delle letture provenienti dai sensori, come le telecamere e il GPS, e del lidar (osservazioni) per ottenere informazioni sullo stato dell’ambiente.
Per apprendere una politica, ovvero per imparare a generare le azioni corrette come la sterzata o la frenata, da queste osservazioni, l’agente tenta ripetutamente di posteggiare il veicolo usando un processo di tentativi ed errori definito “trial-and-error”, cercando di massimizzare un segnale di ricompensa. La ricompensa viene utilizzata per valutare l’efficacia di un tentativo e per indirizzare il processo di apprendimento.
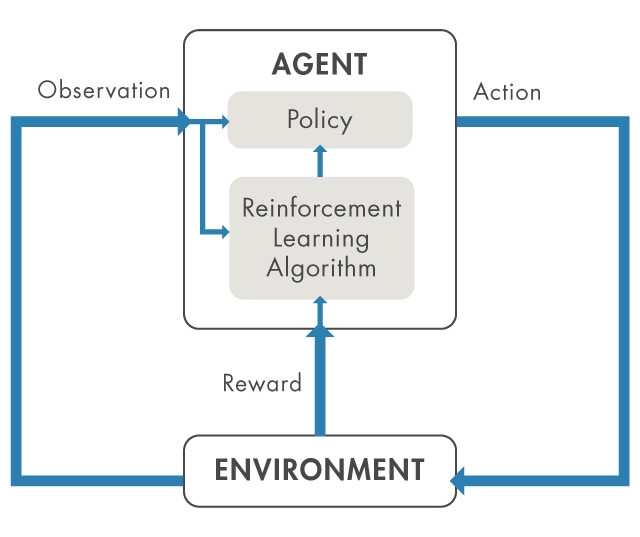
In base alle osservazioni raccolte, alle azioni e alle ricompense, un algoritmo di addestramento procede alla regolazione della politica dell’agente. Dopo l’addestramento, il computer del veicolo dovrebbe essere in grado di effettuare il parcheggio servendosi esclusivamente della politica sottoposta a regolazione e delle letture dei sensori.
Quando si usa il reinforcement learning?
Sono stati sviluppati diversi algoritmi di addestramento per il reinforcement learning. Molti di questi si basano sulle politiche delle reti neurali profonde (Deep Neural Network) che consentono di usare il reinforcement learning in applicazioni quali la guida autonoma (Figura 2), difficilmente gestibili con gli algoritmi tradizionali.
Ad esempio, la progettazione tradizionale dei sistemi di controllo basata sul feedback di fotocamere è piuttosto problematica in quanto richiede una fase di pre-elaborazione molto lunga, ad esempio per l’estrazione delle feature, prima che i frame acquisiti possano essere effettivamente utilizzati in un ciclo di retroazione. Ciononostante, con le DNN la fase di estrazione delle feature entra a far parte della politica della rete neurale, consentendo così di giungere a soluzioni end-to-end.
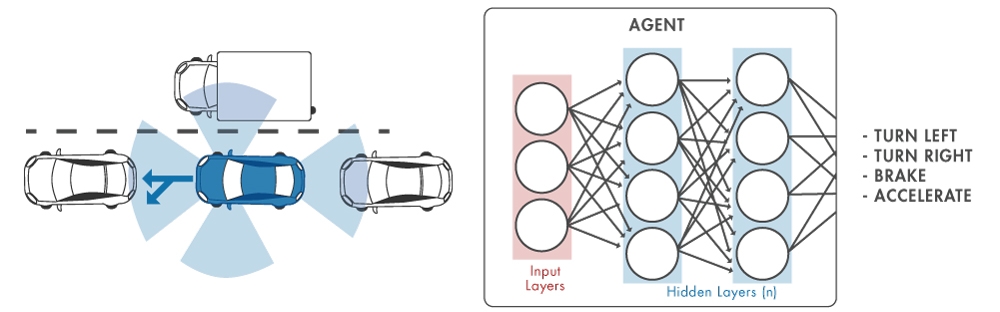
D’altro canto, la problematica posta dagli algoritmi DNN, spesso costituiti da milioni di parametri, risiede proprio nella loro complessità, che non consente di spiegare le decisioni prese dalla rete e rende difficile stabilire delle garanzie di prestazioni formali.
Un altro fattore da calcolare in relazione al reinforcement learning è che non è sottoposto al principio di sample efficiency. Per i progetti che richiedono un’esecuzione rapida con tempi di addestramento limitati, l’approccio del reinforcement learning, oneroso in termini di addestramento, pone ulteriori barriere.
Ad esempio, il tempo di addestramento di questo approccio può andare da qualche minuto a svariati giorni, anche per applicazioni relativamente semplici. Infine, l’ampio numero di decisioni progettuali da prendere per definire un problema di reinforcement learning rende questa stessa operazione di definizione del problema piuttosto complessa, in quanto spesso richiede iterazioni ripetute per arrivare alla soluzione corretta.
Qual è il flusso di lavoro da seguire per risolvere un problema di reinforcement learning?
Nella Figura 3 è rappresentato un flusso di lavoro generale di reinforcement learning per l’addestramento di un agente.
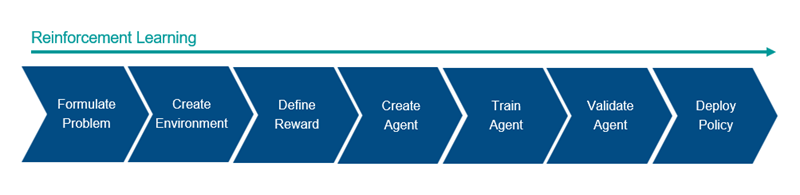
- Formulazione del problema: definire l’attività che l’agente deve apprendere, comprese le modalità con cui l’agente interagisce con l’ambiente e gli eventuali obiettivi primari e secondari che l’agente deve raggiungere.
- Creazione dell’ambiente: definire l’ambiente in cui l’agente opera, compresa l’interfaccia tra agente e ambiente e il modello dinamico di ambiente.
- Definizione della ricompensa: specificare il segnale di ricompensa che l’agente usa per misurare le sue performance rispetto agli obiettivi dell’attività e le modalità con cui questo segnale viene calcolato dall’ambiente.
- Creazione dell’agente: creare l’agente, compresa la definizione di una rappresentazione della politica e la configurazione dell’algoritmo di addestramento dell’agente.
- Addestramento dell’agente: addestrare la rappresentazione della politica dell’agente usando l’ambiente, la ricompensa e l’algoritmo di addestramento dell’agente definiti.
- Convalida dell’agente: valutare le performance dell’agente addestrato simulando contemporaneamente agente e ambiente.
- Distribuzione della politica: distribuire la rappresentazione della politica addestrata usando, per esempio, codice GPU generato.
L’addestramento di un agente tramite reinforcement learning è un processo iterativo. Le decisioni e i risultati delle fasi successive potrebbero richiedere il ritorno a una fase precedente del flusso di lavoro di addestramento. Ad esempio, se il processo di addestramento non converge su una politica accettabile entro un lasso di tempo ragionevole, potrebbe essere necessario aggiornare uno dei seguenti elementi prima di addestrare nuovamente l’agente:
- Impostazioni di addestramento
- Configurazione dell’algoritmo di addestramento
- Rappresentazione della politica
- Definizione del segnale di ricompensa
- Segnali di osservazione e azione
- Dinamica dell’ambiente.
Ad oggi, gli strumenti dedicati al reinforcement learning possono essere utili ad ampliare e a implementare più velocemente i propri controllori e gli algoritmi di decision-making.
Indipendentemente dalla scelta dello strumento, per chi è interessato a introdurre la tecnologia del reinforcement learning nel proprio progetto ma non l’ha mai usata prima, il modo migliore per iniziare è rispondere a queste tre domande e capire se questo è l’approccio giusto.


{kind=link}